

How To Allocate Resources Between Online Services And Batch Jobs
Efficient Resource Management at Pinterest's Batch Processing Platform
Yongjun Zhang | Software Engineer; Ang Zhang | Engineering Managing director; Shaowen Wang | Software Engineer, Batch Processing Platform Squad
This commodity was updated on 3 December 2021.
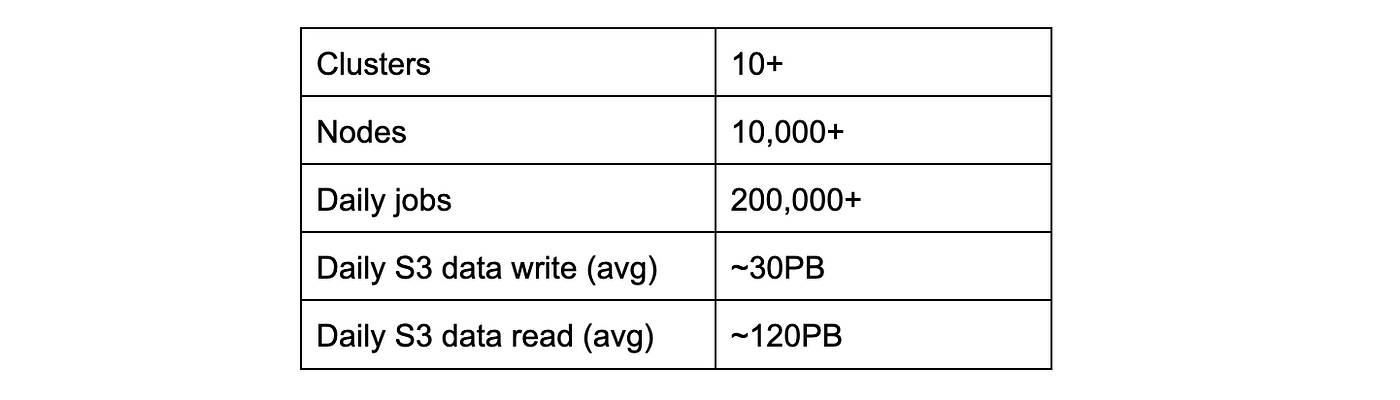
Pinterest'south Batch Processing Platform, Monarch, runs near of the batch processing workflows of the visitor. At the scale shown in Table 1, it is important to manage the platform resource to provide quality of service (QoS) while achieving cost efficiency. This article shares how nosotros practise that and time to come work.
Introduction of Monarch
Figure 1 shows what Pinterest's information organization looks like at a high level. When users are using Pinterest applications on their mobile or desktop devices, they generate various logs that are ingested to our organization via Singer + Kafka (see Scalable and reliable information ingestion at Pinterest) and the resulting information is stored to S3. And so the information is processed and analyzed by various workflows like sanitization, analytics, and automobile learning data preparation. The results of the workflows are typically stored back to S3. In that location are substantially ii types of processing platforms: batch and streaming. This web log is well-nigh the batch processing platform named Monarch. See this blog for more information almost the streaming platform.
Equally an in-firm big data platform, Monarch provides the infrastructure, services, and tools to help users develop, build, deploy, and troubleshoot their batch processing applications (more often than not in the class of workflows) at scale. Monarch consists of more than 20 Hadoop YARN clusters built entirely in the Cloud utilizing AWS EC2, and we use many different instance types offered by EC2. The actual EC2 instance blazon nosotros utilize at a cluster depends on its workload; some clusters are more than optimized for calculating, while others have more than retention or deejay capacity.
User workflows tin can be submitted to Monarch from Spinner (an internal workflow platform built on top of Airflow) and other UI based workflow orchestration tools via Job Submission Service, or JSS (encounter Figure 2). The user workflow source lawmaking typically specifies the cluster and queue in which the workflow should run.
Resource Management Challenges
Hadoop YARN is used to manage the cluster resources and task scheduling. The cluster resources are represented every bit a tree of queues. All the resource of the cluster, or all the EC2 instances the cluster has, are represented as the "root" of the tree, and the leaf nodes of the tree are where applications run. The weight configuration of a queue determines the amount of resources allocated to information technology. Child nodes of the same parent node share the resources allocated to the parent. How much resource a child gets is based on the ratio of this child'south weight over the sum of the weights of all sibling nodes. By setting the node weight, we can control how many EC2 instances are assigned to whatsoever given queue. YARN supports multiple schedulers, and the Fair Scheduler is used in Monarch.
The goal of using a tree of queues to correspond resource allocation is to achieve resource isolation betwixt workflows that run in different queues. However, Monarch initially didn't take a consequent queue structure, as shown in Figure 3. Some queues were allocated to specific projects, some were for organizations, and others for workflows of a sure priority. Every bit a event, at that place was severe interference between different workflows running in the same queue — more critical workflows were oft impacted past non-critical ones.
There were mainly two reasons for interference:
- Workflows running in the same queue are treated the same. With no notion of priority, the scheduler has no way to requite more resource to more critical workflows.
- At that place is a parameter maxRunningApps to control how many applications tin can concurrently run in a given queue. This prevents too many applications competing for resources, in which situation no awarding tin make good progress. Nonetheless, if lower priority workflows are submitted showtime and saturate the maxRunningApps, so critical workflows submitted later tin can be stuck for a long fourth dimension without beingness scheduled.
To accost these bug, nosotros introduced workflow tiering and changed the resource resource allotment queues to be tier-ed appropriately.
Workflow Tiering and Hierarchical Queue Structure
The workloads on Monarch are typically in the form of workflows. Workflow is represented equally a Directed Acyclic Graph (DAG) of multiple jobs to process input information and generate output. The jobs in the aforementioned workflow run in parallel or sequentially depending on whether there is dependency on each other. We took 2 main steps to provide QoS for workflows while achieving cost efficiency.
Firstly, nosotros added tiering to distinguish critical workflows from non-disquisitional ones. The critical workflows typically have higher requirements on the finishing time. We decided to classify workflows into 3 tiers: tier1, tier2, and tier3 (tier1 has the highest importance). And so we worked with user teams to define the tiering and runtime service level objective (SLO) of all workflows that run on the Monarch platform.
Secondly, nosotros changed the resources queue structure beyond all clusters to take the notion of tiering, project, and organisation. Given that each workflow is associated with a project, each project belongs to a team, and each squad belongs to a larger organization, we decided to create a three level hierarchical queue structure: organization, project, and tier. Run across Figure 4 for an example ("default" is used in place of tier3, for historical reason).
Some of the most of import configurations of the queues are:
- Weight: The weight of a queue determines the amount of resource allocated to it. Kid nodes of the aforementioned parent node share the parent'southward resources based on the relative ratio of their weights.
- MaxRunningApps: The maximum number of applications that can run concurrently within the queue. This prevents from having too many applications running in the aforementioned queue of limited resources, meaning no applications can make good progress.
- Preemption:
- preemption: whether to enable preemption
- fairSharePreemptionTimeout: number of seconds the queue is under its fair share threshold before it will endeavor to preempt containers to take resources from other queues.
- fairSharePreemptionThreshold: the fair share preemption threshold for the queue. If the queue waits fairSharePreemptionTimeout without receiving fairSharePreemptionThreshold*fairShare resources, it is allowed to preempt containers to accept resource from other queues.
- allowPreemptionFrom: determines whether the scheduler is allowed to preempt resources from the queue.
Nosotros configure tier1 queues to not allow preemption and also configure the fairSharePreemptionTimeout parameter to smaller values and the fairSharePreemptionThreshold parameter to larger values than for tier2 and tier3 queues. This allows tier1 queues to acquire resources faster when they are not getting their fair share of resources.
Because Monarch has many clusters, and the workflows running on different clusters could change from fourth dimension to time, information technology's not applied or efficient to manually create the queue structures. We developed a tool that analyzes the historical data of the workflows on the clusters, generates the queue construction, and updates the settings automatically and periodically.
Also the preemption configuration described in a higher place, two of the most of import configurations are the queue weight and maxRunningApps. In the adjacent section, we will share more than details on the algorithm nosotros apply to generate these settings.
Resource Allocation Algorithm
The workflows running in a queue have unlike requirements at different times. To ensure QoS of the disquisitional workflows, we designed an algorithm to assign queue weight based on historical run data, namely, the Percentile Algorithm.
The algorithm looks at the historical run information within the most contempo time window, such every bit 30 days, to come across how much resource is needed for a given queue. Below is what it does:
- Step i: The queue may exist used at some times and may be vacant at other times. When the queue is being used, sometimes Ten EC2 instances are existence used and sometimes Y EC2 instances are being used. The algorithm divides the time window into time units; each unit is a timespan that the same number of EC2 instances are used. The time unit of measurement is represented as <timeLength, instanceUsed>. (Run across the left side of Figure five)
- Step 2: Excluding the time units in which the queue is vacant, sort the time units past the number of instances used in the fourth dimension unit (see the correct side of Figure v) from smallest to largest.
- Stride three: Determine the minimum number of instances to allocate to the queue to make sure a pre-specified time length percentage threshold is met. This threshold means, given the total length of time units (TTIU) that the queue is in use, the allocated resource needs to be enough to satisfy the pct of TTIU. For case, for a tier1 queue that is used for 240 hours in full inside a 30-day window (vacant other times), we'd like to guarantee the resource for 95% of the fourth dimension, thus it's 228 hours. The algorithm finds out the number of instances beingness used at the sorted results from Step two. For example, tu0 + tu4 + tu7 + tu2 is nearly 95% of the whole fourth dimension length in use, then the number of instances used in tu2 is the number of instances to exist allocated to this queue. If nosotros were to classify the number of instances used in tu5, which is larger than used in tu2, it would potentially cause waste material because tu5 is only five% of the whole time the queue is in utilise.
The 95% threshold in a higher place is just an example. We evaluated the resource usage of different tiers and came up with different thresholds based on the size of the clusters and resources used by those workflows. The thresholds are also adjusted from time to time when the percentages of resources used past different tiers change.
There are several reasons we don't have to guarantee 100% of the resources required at the summit usage time of a given tier1/tier2 queue, thus avoiding waste product.
- The workflow tiering has a rough distribution such that ~ten% workflows are tier1, 20–xxx% tier2, and 60–70% tier3.
- Not all queues are busy at the aforementioned fourth dimension, and the YARN scheduler allows workflows to employ resources available at other queues.
- Higher tier queues can preempt resources faster.
We measure out the resource headroom of a queue past a metric called usage/capacity ratio. The chapters of a queue is the number of instances allocated to the queue times the length of the time window beingness measured. The usage is measured by YARN as instance-hours. E.chiliad., if the queue uses X instances for Y hours, the resource usage is 10 * Y case-hours. In addition, nosotros besides measure vcore-hours and memory-hours usage/chapters ratio in a like style to see how balanced the vcore and retentivity resource usage is. Notice that YARN reported vcore-hours and memory-hours, and we use the ascendant-resources (DR) method to calculate the example-hours here.
The algorithm ensures the percentage threshold is set up in a decreasing gild from tier1 to tier3 queues, while it also ensures that the usage/capacity ratio is in an increasing order. This means the caput room is the largest for tier1, second for tier2, and smallest for tier3.
The resource allocation algorithm also looks at historical run information to determine the maxRunningApps setting and sets this configuration with some headroom for each queue.
Comparing with Autoscaling
Autoscaling is some other mutual arroyo to save cost in the Cloud, scaling upward the cluster when needed and scaling downward when pinnacle demand has passed. Because Cloud providers unremarkably accuse much higher rates for on-demand capacity than reserved instances, users commonly reserve the chapters that is ever required and use on-need instances for the autoscaling.
Autoscaling works well for online services at Pinterest, but we establish it is not as price efficient for batch processing for the following reasons:
- Tasks from large calibration batch processing can run for hours, and the 2 options to calibration downwards the cluster are wasteful. Scaling down gracefully and waiting for running tasks to terminate (i.e. draining the instances before terminating them) potentially wastes a pregnant corporeality of resources considering the instances may non be fully utilized. Scaling downwardly by terminating instances forcefully even when tasks are still running on them means unfinished computing is wasted (and longer runtime for the involved jobs) and extra resources are needed to rerun the terminated tasks.
- In order for autoscaling using on-demand instances to make economical sense when compared with reserved instances, nosotros estimated the percentage of time of superlative consumption of the cluster using on-demand instances will need to be less than 30% for sure instance types. Considering the time information technology takes to calibration downward, the pct would exist a lot smaller. Withal, it's hard to control this percentage, and resources tin easily be wasted if the percentage goes higher.
- At Pinterest'south large data processing scale, using autoscaling would crave getting hundreds or more instances of desired instance types during tiptop hours, which is not always possible. Not getting enough resources to run critical workflows could affect the business in a significant fashion.
By utilizing the resource allocation algorithm described above and workflow tiering, nosotros were able to utilize skillful reserved case pricing while still guaranteeing enough resource for critical workflows when needed.
Please note that in this blog, we focus on product workflows, not ad hoc workloads like Spark SQL queries from Querybook or PySpark jobs from Jupyter notebooks. On advertisement hoc clusters, nosotros do apply autoscaling with Spot instances considering the peak usage simply lasts 2–3 hours on business organisation days.
Workflow Functioning Monitoring
When allocating resources for a workflow, the runtime SLO is an important factor to consider. For example, if the workflow uses 10 instances-hours resource, and the runtime SLO is 12 hours, then the number of instances needed to run this workflow is X / 12.
With the resource allotment being in outcome, we need a way to monitor the overall workflow runtime performance. We developed a dashboard to bear witness how each tier workflows are performing in various clusters.
Within a time window of a certain size, for any given workflow, if it is run for X times and Y runs run into SLO, its SLO success ratio is divers equally Y/X. It's ideal if this ratio is 100% for whatsoever given workflow, just information technology'south not feasible for many reasons. As a compromise, we define a workflow equally SLO-successful if its SLO success ratio is no less than 90%.
Equally mentioned before, we classified workflows into iii tiers. For workflows of each tier, we measure the percentage of workflows that are SLO-successful. Our goal is to have this percent higher than 90%.
Figure six is a snapshot of the dashboard that measures the performance of the thirty-day time window. Before the projection, the tier1 workflow's success percentage was around seventy%. Information technology has been improved to and stabilized around 90% at present. While nosotros try to make most tier1 workflows successful, the aforementioned metrics of other tiers are not sacrificed too much considering they take less stringent SLO requirements.
Cluster Resource Usage Monitoring
The workflow requirement is not static and may change from time to time. A daily written report is washed for each cluster on the following metrics:
- Total, tier1, tier2, and tier3 usage/chapters ratio (including instance, vcore, retentiveness)
- Number of all tier1, tier2, and tier3 workflows running in the cluster (there may be new workflows onboarded, or re-tiering and SLO change of existing workflows)
Based on these metrics, we decide if the cluster is over or under utilized and have actions past either adding more resources to the cluster (organic growth), downsizing the cluster to save cost, or keeping it as is.
Cross-Cluster Routing And Load Balancing
Equally mentioned earlier, different workflows take different resources needs — some require more memory, some more than CPU, and others more disk IO or storage. Their needs may alter over time. Additionally, some clusters may become full while others are underutilized over time. Through monitoring resource consumption, we may observe better abode clusters for the workflows than their current ones. To ask users to change their source code to move the workflow is a slow process, as nosotros also accept to suit the resources resource allotment when we move the workflow.
We developed a cross-cluster routing (CCR) capability to change the target cluster of the workflows without the demand of users to change settings. To implement this, we added instrumentation logic in the JSS component that tin redirect jobs to another cluster as we demand.
We also developed a workflow to periodically clarify the cluster usage and choose candidate workflows to move to other clusters to go on improving the load balancing and cost efficiency.
To enable redirecting jobs, nosotros need to do resources allocation change on the target cluster with the in a higher place mentioned algorithm. To achieve this, we automatic the resources allotment process such that with a single button click (triggering a workflow), it will do both resource allotment and configure job redirection in one step.
Current and Hereafter Work
At the time of writing, our metrics bespeak the vcore and retentivity usage of a adequately big cluster is not balanced, and a lot of vcores are wasted as a result. We are working on splitting this cluster into ii clusters of dissimilar example types with CCR support and migrating the workflows running on the original cluster into ane of the resulting clusters. We wait with this modify we will be able to not just run the applications more reliably, but also salve a lot of toll.
Our clusters are located at different availability zones. When 1 zone has an issue, we tin can leverage the CCR characteristic to move critical workflows to some other cluster in a different zone. We are working on making this process smoother.
We are also looking into dynamically route jobs at runtime to different clusters when the electric current load on the target cluster is total.
Acknowledgement
Thanks to Hengzhe Guo, Bogdan Pisica, Sandeep Kumar from the Batch Processing Platform team who helped further improve the implementations. Thanks to Soam Acharya, Jooseong Kim and Hannah Chen for driving the workflow tiering. Thanks to Jooseong Kim, William Tom, Soam Acharya, Chunyan Wang for the discussions and back up forth the way. Thanks to the workflow team, our platform user teams for their feedback and back up.
To learn more than virtually engineering at Pinterest, bank check out the rest of our Engineering Web log , and visit our Pinterest Labs site. To view and utilize to open up opportunities, visit our Careers folio.

How To Allocate Resources Between Online Services And Batch Jobs,
Source: https://medium.com/pinterest-engineering/efficient-resource-management-at-pinterests-batch-processing-platform-61512ad98a95
Posted by: wentworthlinet1989.blogspot.com
0 Response to "How To Allocate Resources Between Online Services And Batch Jobs"
Post a Comment